이번에는 지금까지 만든 마스터 노드 1개와 슬레이브 노드 2개로 구성된 환경에서 하둡 파일 시스템(HDFS)을 초기화하고 하둡 클라우드에 디렉토리를 생성하여 파일을 업로드하는 과정을 살펴본다.
1. 초기화 및 네임노드 포맷
하둡을 재구동하기 전, 이전 실행 기록이 남아 충돌하는 것을 막기 위해 임시 디렉토리(/usr/local/hadoop/tmp)를 비우는 작업을 선행한다. master와 모든 slave 노드에서 동일하게 진행한다.
공통사항: 기존 tmp 폴더를 삭제 후 재생성하고, username에게 소유권 권한을 부여
rm -rf /usr/local/hadoop/tmp
mkdir /usr/local/hadoop/tmp
chown username: -R /usr/local/hadoop/tmp
[master]
HDFS의 메타데이터를 관리하는 네임노드를 포맷한다. 이 명령어를 수행하면 기존 HDFS 내의 모든 데이터가 삭제되므로 주의해야 한다.
cd /usr/local/hadoop/bin
hadoop namenode -format
2. 데몬 실행
[master]
start-all.sh
jps # NameNode 등 확인
[slave1, 2]
# DataNode 개별 시작 시도
hadoop-daemon.sh start datanode
# 만약 프로세스가 꼬여있다면 강제 종료 후 재시작
kill -9 [PID]
hadoop-daemon.sh start datanode
jps
# 결과: DataNode가 떠 있는지 확인
3. 웹 UI를 통한 클러스터 상태 확인
모든 데몬이 정상적으로 떴다면, 네임노드의 웹 인터페이스에 접속하여 클러스터 상태를 시각적으로 확인한다.
- firefox http://master:50070
- 'Live Nodes' 항목에 Slave 노드 2대가 정상적으로 카운트되는지 확인.


4. HDFS 디렉토리 생성 및 파일 업로드 테스트
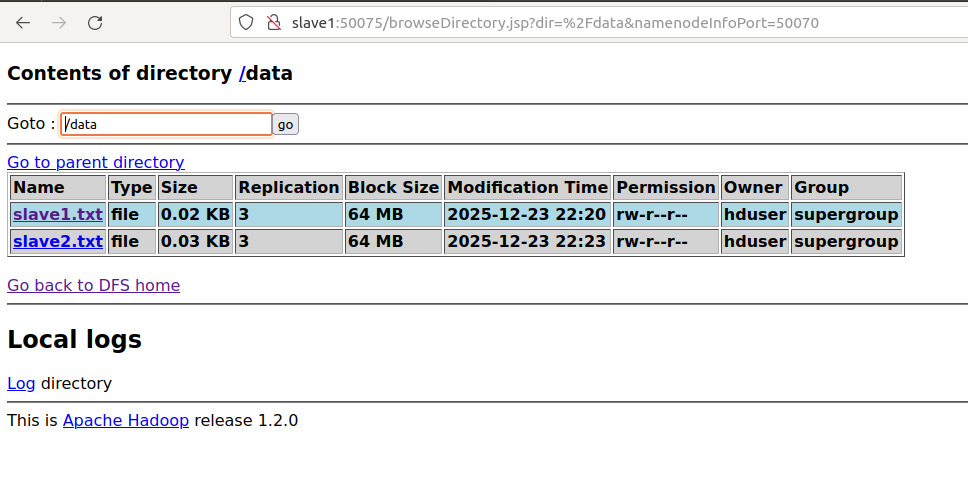
마지막으로 HDFS가 제대로 동작하는지 확인하기 위해 디렉토리를 생성하고, 각 슬레이브 노드에서 생성한 로컬 파일을 HDFS로 업로드한다.
[master] 디렉토리 생성
hadoop fs -ls / # 루트 조회
hadoop fs -mkdir /data # 테스트용 data 디렉토리 생성
[slave1, 2]
각 슬레이브 노드에서 테스트용 텍스트 파일을 만들고 HDFS의 /data 경로에 업로드한다. put과 copyFromLocal 명령어 모두 동일하게 동작함을 알 수 있다.
# slave1에서 수행
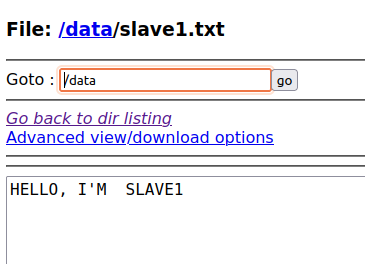
echo "HELLO, I'M SLAVE1" > slave1.txt
hadoop fs -put slave1.txt /data/
# slave2에서 수행
echo "HELLO, I'M SLAVE2" >> slave2.txt
hadoop fs -copyFromLocal slave2.txt /data/
결과 확인
master 또는 slave에서 hadoop fs -ls /data/ 명령어로 조회하거나, firefox http://master:50070 로 UI를 통해 확인할 수 있다.

'AI Journey > 클라우드' 카테고리의 다른 글
| [Docker] 도커의 아키텍처와 동작 원리, 기술 동향 정리 (0) | 2025.12.26 |
|---|---|
| 도커(Docker)와 컨테이너 기술의 개념 이해하기 (2) | 2025.12.24 |
| Hadoop 클러스터 구축하기 part.2 - SSH 키 기반 연결, 하둡 환경 설정 및 배포 (0) | 2025.12.23 |
| 가상환경에서 Hadoop 클러스터 구축하기 part.1 - 호스트네임, 네트워크 설정 (0) | 2025.12.22 |
| [VMware] 가상머신 안에서 가상화를 할 때 반드시 필요한 설정 (0) | 2025.12.18 |

