SSH 서버 설치 키 설정이 끝났다면, 이제 하둡 설치 파일을 압축 해제하고 시스템 환경 변수 및 핵심 설정 파일들을 수정하여 마스터 노드 서비스를 실제로 가동할 차례다.
1. 하둡 설치 및 권한 설정
cd ./Desktop
# -C 옵션으로 특정 디렉터리(/usr/local/)에 tar.gz 압축 풀기
tar xvfz hadoop-1.2.0.tar.gz -C /usr/local/
#디렉토리명을 hadoop 짧게 변경
mv hadoop-1.2.0/ /usr/local/hadoop
#hadoop 디렉토리와 그 하위의 모든 파일(-R)에 대해 모든 사용자에게 읽기, 쓰기, 실행 권한을 부여
chmod 777 -R /usr/local/hadoop/
#hadoop 디렉토리의 소유자와 그룹을 root에서 [username]으로 변경
chown [username]:[username] -R /usr/local/hadoop다운로드한 하둡 바이너리 파일을 시스템 폴더로 옮기고, 사용 권한을 부여한다.
- 수행 작업: tar xvfz 명령어로 압축을 해제하여 /usr/local/로 전송한다. 디렉터리 이름을 hadoop으로 단순화하고, chmod와 chown을 이용해 [username]이 모든 권한을 갖도록 설정한다.
- 목적: 하둡 실행 파일을 시스템 공용 디렉터리에 배치하고, 하둡 전용 계정( [username] )이 자유롭게 읽고 쓸 수 있는 환경을 만든다.
- 핵심 내용: 설치 경로 확보 및 권한 위임. sudo 명령을 통해 관리자(root) 권한으로 설치를 하지만, 실제 운영은 [username]이 하도록 소유권을 변경해야 한다.
2. 하둡 환경 변수 설정
nano ~/.bashrc
<nano 편집기>
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#수정한 환경 설정 파일을 시스템에 즉시 적용 (재부팅이나 재로그인 효과)
source ~/.bashrc시스템 어디서든 hadoop 명령어를 사용할 수 있도록 로그인한 사용자의 환경 설정 파일(~/.bashrc)에 경로를 등록한다.
- 수행 작업: ~/.bashrc 파일에 $HADOOP_HOME 변수를 정의하고, bin과 sbin 폴더를 기존 실행 경로($PATH)에 추가한다.
- 목적: hadoop, start-all.sh 같은 명령어를 전체 경로 입력 없이 바로 실행하기 위함이다.
- 핵심 내용: 커맨드 라인 편의성 확보. 환경 변수 설정이 누락되면 이후 명령어 실행 시 'Command not found' 오류가 발생한다.
3. 하둡 핵심 환경 설정 파일 편집
#원본 파일을 보존하기 위해 백업 파일(.bak)을 생성. -arp: 권한과 속성을 그대로 유지하며 복사
cp -arp [원본] [대상].bak
nano -c [파일명] #-c: 에디터 하단에 현재 편집 중인 행 번호를 보여줌.
/*
hadoop-env.sh
core-site.xml
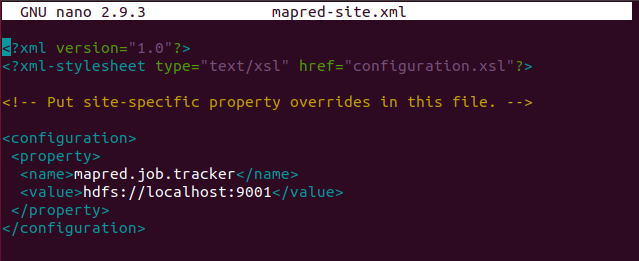
mapred-site.xml
*/
mkdir /usr/local/hadoop/tmp #하둡 데이터를 임시로 저장할 실제 폴더를 생성하둡의 동작 방식, 자바 경로, 임시 디렉터리 위치 등을 정의하는 가장 중요한 단계다.
- 수행 작업: 각 설정 파일의 백업(.bak)을 생성한 후 nano 에디터로 수정한다.
- hadoop-env.sh: 하둡이 사용할 자바 경로(JAVA_HOME)와 네트워크 옵션(IPv4Stack) 설정.
- core-site.xml: 네임노드 주소(hdfs://localhost:9000)와 임시 파일 저장 경로(tmp) 설정.
- mapred-site.xml: 맵리듀스 작업 관리자인 잡트래커(JobTracker) 주소 설정.
- 목적: 하둡 클러스터가 어떻게 통신하고 데이터를 어디에 저장할지 상세 설계도를 작성하는 과정이다.
- 핵심 내용: 클러스터 파라미터 정의


4. 파일 시스템 초기화 및 서비스 시작
hadoop namenode -format #하둡의 메타데이터를 저장하는 네임노드를 초기화
start-all.sh #설정된 모든 하둡 서비스를 한꺼번에 구동하둡의 파일 시스템(HDFS)을 포맷하고 모든 서비스를 가동한다.
- 수행 작업: tmp 디렉터리를 생성하고, hadoop namenode -format 명령어로 파일 시스템을 초기화한다. 그 후 start-all.sh 명령으로 모든 프로세스를 실행한다.
- 목적: 윈도우를 설치할 때 하드디스크를 포맷하듯, 하둡 전용 파일 시스템 구조를 생성하고 마스터 노드의 모든 기능을 활성화한다.
- 핵심 내용: HDFS 포맷. 포맷은 최초 1회만 수행해야 하며, 반복 수행 시 기존 데이터가 손실될 수 있으니 주의해야 한다.
5. 데몬 프로세스 실행 확인
하둡의 필수 데몬 프로세스들이 메모리상에서 정상적으로 실행 중인지 확인한다.
💡하둡은 자바(Java) 언어로 개발된 프레임워크이므로 네임노드(NameNode), 데이터노드(DataNode)와 같은 하둡의 각 구성 요소들은 독립적인 자바 프로세스 형태로 구동된다. 리눅스 시스템 입장에서는 이들이 하둡인지 일반 자바 프로그램인지 구분하지 않고, 단지 java라는 이름의 프로세스가 실행 중인 것으로 인식한다.
jps #현재 실행 중인 자바(Java) 프로세스 목록 조회
hadoop-daemon.sh start [프로세스명] #전체 실행 시 누락되거나 꺼진 서비스만 개별적으로 실행할 수 있음- 수행 작업: 현재 실행 중인 자바 프로세스 목록을 확인한다. 실행 확인이 안 되는 프로세스는 hadoop-daemon.sh로 개별 실행할 수 있다.
- 목적: 마스터 노드가 제 역할을 하기 위해 필요한 데몬 프로세스들이 떠 있는지 체크한다.
- 핵심 내용: 5개 데몬 실행 확인. 다음의 프로세스 목록이 모두 보여야 마스터 노드 구축이 완료된 것이라고 볼 수 있다.

만약 hadoop-daemon.sh start [프로세스명]을 실행해도 프로세스가 뜨지 않으면 rm -rf /usr/local/hadoop/tmp를 해서 디렉토리를 삭제하고 mkdir /usr/local/hadoop/tmp 부터 다시 실행한다.
지금까지는 단일 노드(마스터 노드)를 세팅했으니, 다음 포스팅부터는 지금까지 구축한 마스터 노드와 함께 클러스터를 구성하는 슬레이브 노드들을 만들어 보기로 한다.
'AI Journey > 리눅스' 카테고리의 다른 글
| [Linux] /etc/hosts 파일 이해하기 (0) | 2026.01.01 |
|---|---|
| [Linux] 데비안 계열 리눅스에서 패키지 설치 오류(Coud not get lock...)문제 해결 방법 (0) | 2025.12.21 |
| [Linux] Hadoop 마스터 노드 구축하기 part.2 - APM 스택, SSH 서버 구축 및 SSH 키 생성 (0) | 2025.12.18 |
| [Linux] Hadoop 마스터 노드 구축하기 part.1 - 자바 설치 및 환경변수 설정 (0) | 2025.12.18 |
| [Linux] LAMP 스택 - 리눅스에 ownCloud 서버 구축하기 (0) | 2025.12.17 |

