지난 글에서는 온도 데이터 시각화 시스템의 시퀀스와 개발 아키텍처를 간단하게 정의해 보았다. 이번에는 어쩌면 시스템에서 가장 중요하다고 할 수 있는 DB 스키마를 정의해보려고 한다.
일일이 노가다로 테이블을 정의하면 공부에는 더 도움이 되겠지만, 이미 할 일이 많은 바쁜 상황에서 더 효율적인 방법이 있는데 굳이 돌아가며 시간을 쓸 필요는 없는 것 같다. 그래서 챗GPT에게 시스템에 대한 기본적인 시퀀스와 시각화하고 싶은 자료에 대한 아이디어를 주고 DB 설계에 대한 명세서를 작성해달라고 했다.
✏다음은 내가 ChatGPT와 협업해서 설계한 DB 명세다.
시스템 개요
ESP32 + 온도센서를 통해 수집된 온도 데이터를 기반으로 웹 대시보드에서 시각화 및 통계 자료를 사용자에게 제공한다. 데이터는 백엔드 서버를 통해 DB에 저장되고, MCP 서버/호스트에서 가공 및 분석되어 사용자에게 제공된다.
주요 시각화 및 분석 요구사항
- 현재 온도 표시
- 날짜별 온도 변화 추이 (년/월/일)
- 시간대별 온도 변화 추이
- 일/주/월 단위 최고·최저·평균 온도
- 이상치(Outlier) 탐지 및 표시
- 임계값 초과/미달 이력
테이블 설계
내가 구상하고 있는 시스템은 ESP32 한 대만 사용하는 시스템이기 때문에 device_id는 사실상 고정된 값이고, 외래키로 참조할 대상(devices 테이블 등) 자체가 없기 때문에 외래키가 불필요하다.
따라서 관계(Relation)도 정의될 필요가 없는 단순한 테이블로 정의가 가능하다.
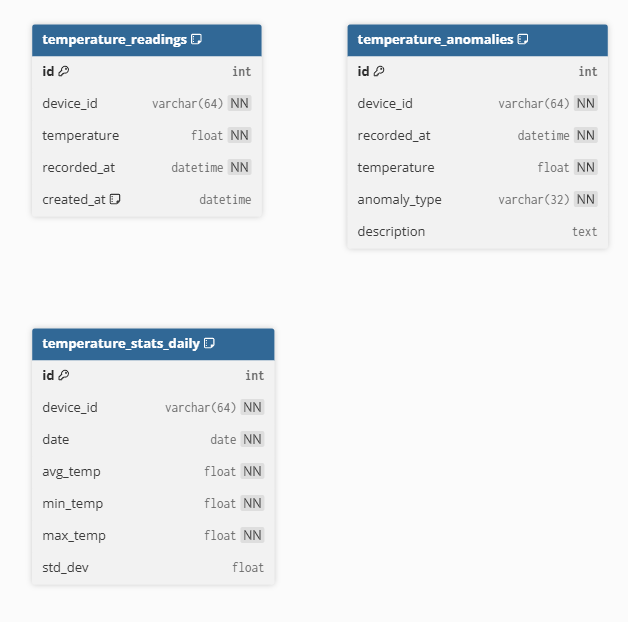
1. temperature_readings (원본 온도 데이터)
| 필드명 | 타입 | 제약 조건 | 설명 |
| id | INT | PK, AUTO_INCREMENT | 고유 식별자 |
| device_id | VARCHAR(64) | NOT NULL | ESP32 기기 식별자 (예: MAC 주소) |
| temperature | FLOAT | NOT NULL | 섭씨 온도 값 |
| recorded_at | DATETIME | NOT NULL | 측정 시각 (기기 기준) |
| created_at | DATETIME | DEFAULT CURRENT_TIMESTAMP | 수신 시각 (서버 기준) |
인덱스: (device_id, recorded_at)
2. temperature_stats_daily (일 단위 통계 데이터)
| 필드명 | 타입 | 제약 조건 | 설명 |
| id | INT | PK, AUTO_INCREMENT | 고유 식별자 |
| device_id | VARCHAR(64) | NOT NULL | 기기 식별자 |
| date | DATE | NOT NULL | 해당 날짜 |
| avg_temp | FLOAT | NOT NULL | 평균 온도 |
| min_temp | FLOAT | NOT NULL | 최저 온도 |
| max_temp | FLOAT | NOT NULL | 최고 온도 |
| std_dev | FLOAT | NULL | 온도의 표준편차 (선택 저장) |
인덱스: (device_id, date)
제약조건: (device_id, date) 유니크
3. temperature_anomalies (이상 탐지 이력)
| 필드명 | 타입 | 제약 조건 | 설명 |
| id | INT | PK, AUTO_INCREMENT | 고유 식별자 |
| device_id | VARCHAR(64) | NOT NULL | 기기 식별자 |
| recorded_at | DATETIME | NOT NULL | 이상 발생 시점 |
| temperature | FLOAT | NOT NULL | 해당 시점 온도 |
| anomaly_type | VARCHAR(32) | NOT NULL | 이상 유형 (HIGH_TEMP, LOW_TEMP, OUTLIER 등) |
| description | TEXT | NULL | 탐지 설명 또는 부가 정보 |
인덱스: (device_id, recorded_at)
ERD 생성 팁 : dbdiagram.io
이번에 ERD를 무료로 그려주는 사이트도 처음 이용해봤다.
여러 사이트를 찾아봤지만, 내가 느끼기에 GPT와 협업해서 사용하기 가장 편한 ERD 생성 사이트는 dbdiagram.io인 것 같다. dbdiagram.io에서 사용하는 DSL(Domain Specific Language)은 DBML (Database Markup Language)이라는 문법을 따르는데, 이 역시 GPT를 이용해 빠르게 작성이 가능하기 때문에, GPT를 시켜서 작성하고 복붙만 하면 아래 그림과 같이 바로 ERD를 생성할 수 있다.
(역시 관계가 정의되지 않은 테이블이라 화살표 없는 밋밋한 ERD가 나온다.)
🔹 ERD 생성에 사용한 DBML :
Project TemperatureMonitoring {
database_type: "MySQL"
}
Table temperature_readings {
id int [pk, increment]
device_id varchar(64) [not null]
temperature float [not null]
recorded_at datetime [not null]
created_at datetime [default: `CURRENT_TIMESTAMP`]
Indexes {
(device_id, recorded_at)
}
}
Table temperature_stats_daily {
id int [pk, increment]
device_id varchar(64) [not null]
date date [not null]
avg_temp float [not null]
min_temp float [not null]
max_temp float [not null]
std_dev float
Indexes {
(device_id, date) [unique]
}
}
Table temperature_anomalies {
id int [pk, increment]
device_id varchar(64) [not null]
recorded_at datetime [not null]
temperature float [not null]
anomaly_type varchar(32) [not null]
description text
Indexes {
(device_id, recorded_at)
}
}
이제부터는 슬슬 DB와 서버를 구축해 봐야겠다.
'AI Journey > 웹' 카테고리의 다른 글
| 실시간 웹 애플리케이션의 핵심, 웹소켓 (WebSocket) 이해하기 (3) | 2025.07.26 |
|---|---|
| Mocking 개념에 대해 알아보자 (0) | 2025.07.09 |
| MCP 프로젝트 : 온도 데이터 시각화 시스템 Part 1 - Plan (1) | 2025.07.08 |
| [개발 용어] Repaint와 Reflow 쉽게 이해하기 (2) | 2025.03.20 |
| [개발 용어] Dev container (데브 컨테이너) Part 2 - 작성 방법 및 예시 (0) | 2025.03.10 |



